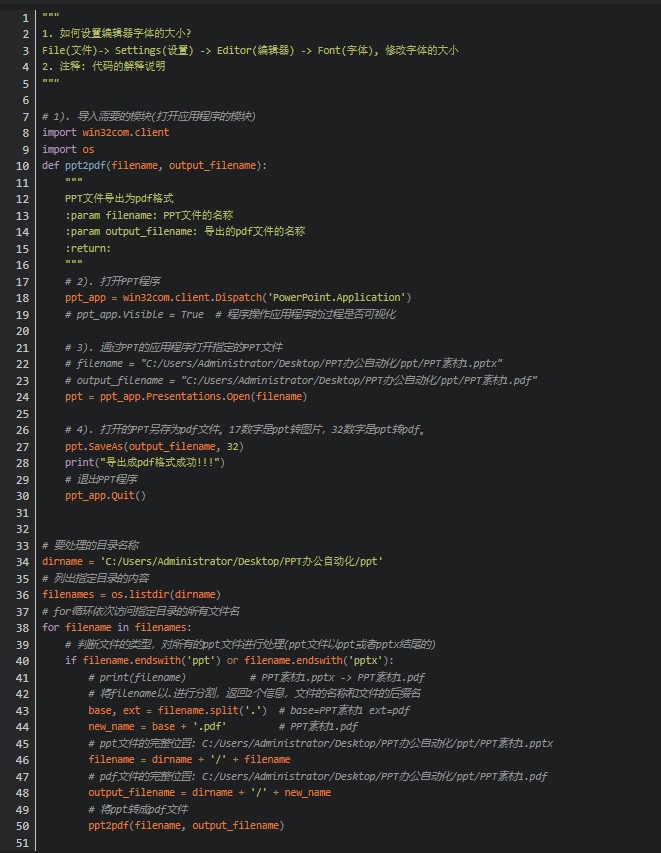
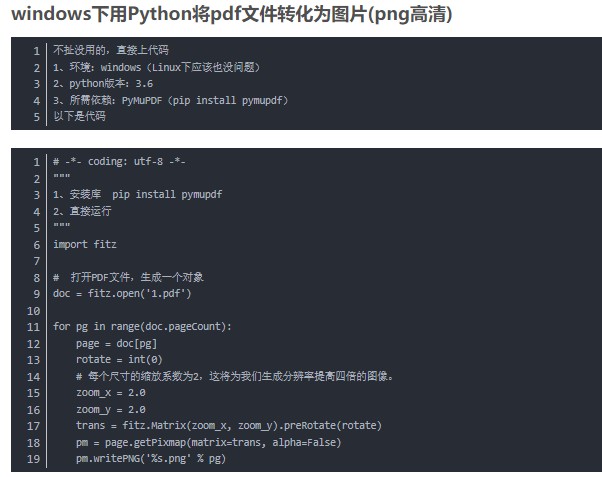
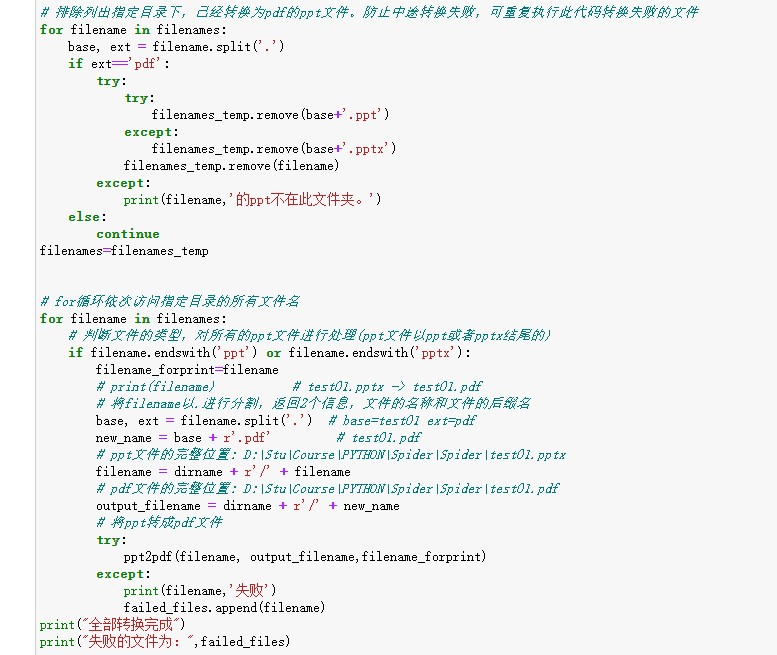
import os
import comtypes.client
def export_presentation(path_to_ppt, path_to_folder):
if not (os.path.isfile(path_to_ppt) and os.path.isdir(path_to_folder)):
raise "Please give valid paths!"
powerpoint = comtypes.client.CreateObject("Powerpoint.Application")
# Needed for script to work, though I don't see any reason why...
powerpoint.Visible = True
powerpoint.Open(path_to_ppt)
# Or some other image types
powerpoint.ActivePresentation.Export(path_to_folder, "JPG")
#这里可以写成:
#Presentation.Slides[1].Export("C:/path/to/jpg.jpg","JPG",800,600);
powerpoint.Presentations[1].Close()
powerpoint.Quit()