
目录
第一种爬虫的方法是通过Urllib 和 BeautifulSoup。主要针对直接爬取网页数据内容的场景,体现在不用对网页进行键鼠操作,且抓取的数据量较大。基本的操作流程逻辑是:
- 将自己的Python代码通过参数伪装成正常的浏览器访问
- 通过改变对Url(及直接操作浏览器输入框网址)来抓取浏览器的所有内容
- 通过RE正则匹配去获得批量的数据
- 将数据保存输出
接下来我们将通过豆瓣电影TOP250排行数据进行实例爬取,在豆瓣的这个网页中,只需要不断改变前后页就可以得到所有排行的数据,不需要模拟键鼠操作,只需要在输入框改变参数(https://movie.douban.com/top250?start=25&filter=),之后在网页元素中取出想要的数据,然后重复操作这个步骤即可。
调试urllib库
get请求
# 导入urllib.request库
import urllib.request
'''
给浏览器发出一个打开百度的get请求
通过response来获取返回的结果
打印查看结果出
'''
response=urllib.request.urlopen("http://www.baidu.com")
# 单条输出
print(response,('\n'+'-'*50)*5)
# html jss
print(response.read(),('\n'+'-'*50)*5)
# 更加可读的模式
response=urllib.request.urlopen("http://www.baidu.com")
print(response.read().decode('utf-8'))
s
post请求
# 导入urllib.parse库
import urllib.parse
'''
获取一个post请求
测试网址:https://httpbin.org/post
post内容为{hello world}字典值
以utf-8可读模式打印返回的结果
'''
url='https://httpbin.org/post'
data=bytes(urllib.parse.urlencode({"hello":"world"}),encoding="utf-8")
try:
# timeout=0.01 太短即可报错
response=urllib.request.urlopen(url,data=data,timeout=0.8)
print(response.read().decode("utf-8"))
except urllib.error.URLError as e:
# 超时处理 报警超时错误
print("timeout")
爬虫伪装
# 伪装
'''
默认python请求没有任何参数
若网站开启审查,即会被ban
显示418错误:我是一个茶壶
'''
url='https://www.douban.com'
response=urllib.request.urlopen(url)
print(response.status)

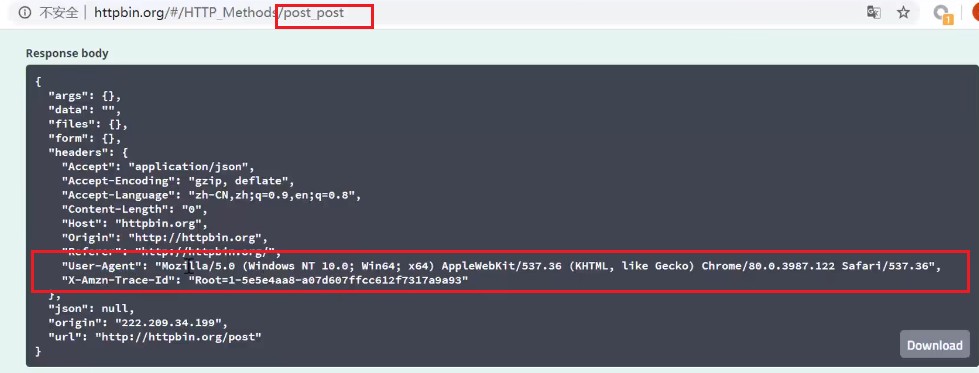
以httpbin.org来debug,伪装自己的参数数值。网络-点击头-标头
下面的代码可以查看请求的参数:
print(response.getheaders())
print(response.getheader(‘Server’))
url='https://www.douban.com'
# 伪装自己是Chrome浏览器
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36'
}
data=bytes(urllib.parse.urlencode({"name":"world"}),encoding="utf-8")
# 伪装headers等参数
req=urllib.request.Request(url=url,data=data,headers=headers,method="POST")
response=urllib.request.urlopen(req)
print(response.read().decode('utf-8'))
调试BeautifulSoup
'''
以utf-8解析百度网页所有内容 同F12
通过BeautifulSoup以html方法解析到bs中
'''
from bs4 import BeautifulSoup
file=open("./Baidu.html","rb")
html=file.read().decode('utf-8')
bs=BeautifulSoup(html,"html.parser")
print(bs)
# 第一种,通过Tag标签得到内容
print(bs.title)
print(bs.a)
# print(bs.head)
# 查看bs属性:<class 'bs4.element.Tag'>
print(type(bs.a))
# 第二种,通过NavigableString得到内容
print(bs.title.string)
print(type(bs.title.string))
print(bs.a.attrs) # 字典
print(type(bs.a.attrs))# 字典
# 第三种,通过整个文档得到内容
print(bs)
# 第四种,通过内容遍历得到内容
print(bs.head.contents)
文档的搜索
import re
from bs4 import BeautifulSoup
file=open("./Baidu.html","rb")
html=file.read().decode('utf-8')
bs=BeautifulSoup(html,"html.parser")
# (1)find_all(),字符串过滤,查找所有与字符串匹配的
t_list=bs.find_all("a") #有"a"就匹配
print(t_list[:10])
# (2)正则表达示,RE
t_list=bs.find_all(re.compile("a")) #有"a"就匹配
print(t_list[:10])
# (3)kwargs 参数索引
t_list=bs.find_all(id="head") #匹配id值="head"
t_list=bs.find_all(class_=True)#匹配有class这个类别
t_list=bs.find_all(class_="mnav")#匹配class值="mnav"
print(t_list[:10])
# (4)text参数
t_list=bs.find_all(text=['hao123','贴吧'])
# 通过RE实现
t_list=bs.find_all(text=re.compile(r"hao123|贴吧"))
print(t_list[:10])
# (5)limit 参数,限定数目
t_list=bs.find_all(text=re.compile(r"\d"),limit=1)
print(t_list)
# (6)css选择器
t_list=bs.select("a") # 通过标签有a
t_list=bs.select(".mnav") #通过类名
t_list=bs.select("a[class='mnav']") #通过属性
t_list=bs.select("head>title") # 通过子标签
t_list=bs.select(".mnav~.bri") # 兄弟标签
实现代码
#-*- codeing= utf-8 -*-
from bs4 import BeautifulSoup
import re
import urllib.request,urllib.error
import sqlite3
import sys
def main():
baseurl="https://movie.douban.com/top250?start=" #ipconfig/flushdns
savepath="./"
getData(baseurl)
# saveData(savepath)
askUrl(baseurl)
#爬取网页
def getData(baseurl):
datalist=[]
for i in range(0,2):
url=baseurl+str(i*25)
html=askUrl(url)
#逐一解析数据
soup=BeautifulSoup(html,"html.parser")
for item in soup.find_all('div',class_="item"):
# print(item) # 查看所有电影信息
item=str(item)
# print(item)
data=[] #保存一部电影所有信息
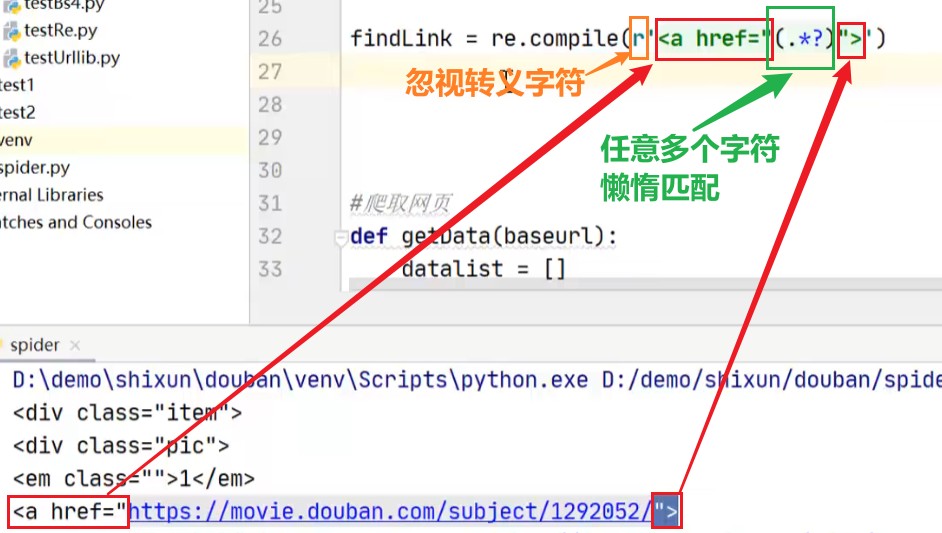
link=re.findall(r'<a href="(.*?)">',item)[0]
data.append(link)
rating=re.findall(r'<span class="rating_num" property="v:average">(.*?)</span>',item)[0]
data.append(rating)
imag=re.findall(r'<img.*src="(.*?)"',item,re.S)[0]
data.append(imag)
print(data)
datalist.append(data)
return datalist
#得到指定网页内容
def askUrl(url):
header={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36'}
request=urllib.request.Request(url=url,headers=header)
try:
response=urllib.request.urlopen(request)
html=response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
return html
# 保存数据
def saveData(savepath):
return 0
if __name__=="__main__":
main()
正则表达式方法,18:00
Wonderful article! We are linking to this great article on our site. Keep up the good writing. Stan Mossey
There is certainly a great deal to know about this topic. I really like all the points you made. Harrison Betschart
Well I sincerely enjoyed studying it. This tip procured by you is very useful for correct planning. Benedict Knapke
Here is a great Weblog You might Find Fascinating that we encourage you to visit. Antone Lietzke
Way cool! Some very valid points! I appreciate you penning this article and also the rest of the website is also really good. Amado Giese