
目录
爬虫第二种是通过Selenium。Selenium更像主流Python爬虫使用方法,其中涵盖很多函数可以对网页进行模拟键鼠的操作,相比第一种方法,对新手更加友好而且功能也更加强大。网上的抢票软件、自动签到和爬取信息很多都是通过Selenium实现的,而且也有丰富的资源。基本的操作流程逻辑是:
- 依据你人工的在网页上的每一步行为
- 通过代码描述出来
- 让程序依次去执行并输出结果
前期准备
确保Chrome浏览器安装好以后,打开下面的连接,访问Chrome 浏览器的驱动下载页面Chrome 浏览器驱动下载地址,将文件储存在D:/…..位置。
# 安装selenium库
!pip install selenium
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
通过WebDriver对象选择元素
# 创建 WebDriver 对象,指明在D:/.....位置使用chrome浏览器驱动
wd=webdriver.Chrome(service=Service(r'D:\Software\chromedriver_win32\chromedriver.exe'))
# 访问百度
wd.get("http://www.baidu.com")
使用 find_elements 选择的是符合条件的所有元素,如果没有符合条件的元素,返回空列表[ ]
使用 find_element 选择的是符合条件的第一个元素,如果没有符合条件的元素,抛出 NoSuchElementException 异常
By.ID
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
# 创建 WebDriver 对象,指明使用chrome浏览器驱动
wd=webdriver.Chrome(service=Service(r'D:\Software\chromedriver_win32\chromedriver.exe'))
wd.get("https://www.byhy.net/_files/stock1.html")
# 根据id选择元素,返回的就是该元素对应的WebElement对象
element=wd.find_element(By.ID,"kw")
# 在选中的输入框内输入通讯
element.send_keys("通讯\n")
By.CLASS_NAME
wd.find_element(By.CLASS_NAME, 'password').send_keys('sdfsdf')
By.TAG_NAME
wd.find_element(By.TAG_NAME, 'input').send_keys('sdfsdf')
By.CSS_SELECTOR
wd.find_element(By.CSS_SELECTOR,'button[type=submit]').click()
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
# 创建 WebDriver 实例对象,指明使用chrome浏览器驱动
wd = webdriver.Chrome(service=Service(r'D:\Software\chromedriver_win32\chromedriver.exe'))
# WebDriver 实例对象的get方法 可以让浏览器打开指定网址
wd.get('https://cdn2.byhy.net/files/selenium/sample1.html')
'''
根据 tag name 选择元素,返回一个列表
里面都是 tag 属性值为 div 的元素对应的对象
'''
elements = wd.find_elements(By.TAG_NAME, 'div') #span
'''
取出列表中的每个 WebElement对象,打印出其text属性的值
text属性就是该 WebElement对象对应的元素在网页中的文本内容
'''
for element in elements:
print(element.text)
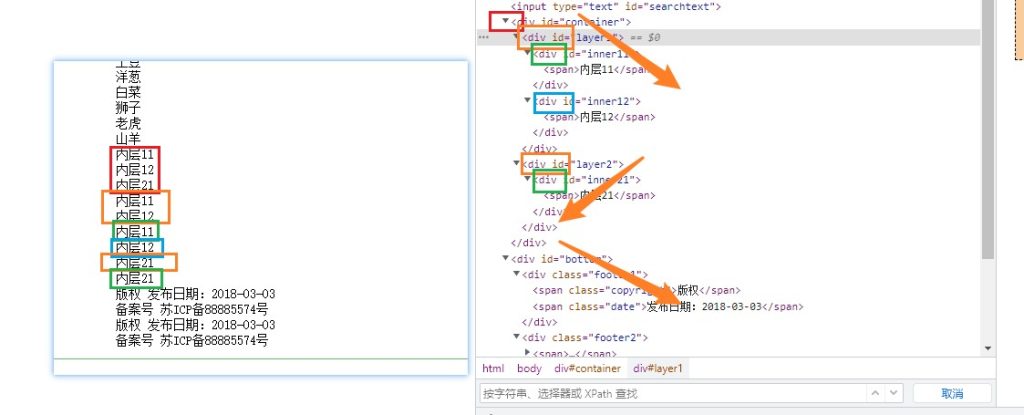
通过WebElement对象选择元素(嵌套)
不仅WebDriver对象有选择元素的方法,WebElement对象也有选择元素的方法。
在WebDriver对象中调用find_element(s)选择WebElement对象后,
还可以对WebElement继续调用find_element(s)选择元素内部的内容对象。
WebDriver 对象选择元素的范围是整个web页面,
而WebElement 对象选择元素的范围是该元素的内部。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
wd = webdriver.Chrome(service=Service(r'D:\Software\chromedriver_win32\chromedriver.exe'))
wd.get('https://cdn2.byhy.net/files/selenium/sample1.html')
#element是WebDriver对象调用find_element得到的WebElement 对象
element = wd.find_element(By.ID,'container')
# 对element(WebElement 对象)调用find_element得到对element内部的元素
spans = element.find_elements(By.TAG_NAME, 'span')
for span in spans:
print(span.text)
等待界面元素出现
在进行网页操作的时候, 有的元素内容不是可以立即出现的, 可能会等待一段时间。
比如我们的股票搜索示例页面, 搜索一个股票名称, 我们点击搜索后, 浏览器需要把这个搜索请求发送给服务器, 服务器进行处理后,再把搜索结果返回给我们。
所以,从点击搜索到得到结果,需要一定的时间,
只是通常 服务器的处理比较快,我们感觉好像是立即出现了搜索结果。
延迟等待
# 等待 1 秒
from time import sleep
sleep(1)
# 具体时间无法确定,造成了大量时间浪费
隐式等待
Selenium提供了一个更合理的解决方案,是这样的:当发现元素没有找到的时候, 并不立即返回找不到元素的错误。而是周期性(每隔半秒钟)重新寻找该元素,直到该元素找到,或者超出指定最大等待时长,这时才抛出异常(如果是 find_elements 之类的方法, 则是返回空列表)。Selenium 的 Webdriver 对象 有个方法叫 implicitly_wait ,可以称之为 隐式等待 ,或者全局等待 。
该方法接受一个参数, 用来指定 最大等待时长。
'''
如果找不到元素, 每隔半秒钟再去界面上查看一次,
直到找到该元素, 或者过了10秒最大时长。
'''
#wd = webdriver.Chrome(service=Service(r'D:\Software\chromedriver_win32\chromedriver.exe'))
wd.implicitly_wait(10)
点击元素
wd.find_element(By.CSS_SELECTOR,'button[type=submit]').click()
操作输入框
element = wd.find_element(By.ID, "input1")
element.clear() # 清除输入框已有的字符串
element.send_keys('新的输入') # 输入新字符串
获取元素信息
获取元素的文本内容
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
wd = webdriver.Chrome(service=Service(r'D:\Software\chromedriver_win32\chromedriver.exe'))
wd.implicitly_wait(10)#最大10秒
wd.get('https://www.byhy.net/_files/stock1.html')
element = wd.find_element(By.TAG_NAME, 'strong')
print(element.text)
获取输入框里面的文字
对于input输入框的元素,要获取里面的输入文本,用text属性是不行的,这时可以使用
- element.get_attribute(‘value’)
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
wd = webdriver.Chrome(service=Service(r'D:\Software\chromedriver_win32\chromedriver.exe'))
wd.implicitly_wait(10)#最大10秒
wd.get('https://www.byhy.net/_files/stock1.html')
element = wd.find_element(By.ID, 'kw')
# 未输入,返回空
print(element.get_attribute('value'))
# 输入后,返回‘通讯’
element.send_keys('通讯\n')
print(element.get_attribute('value'))
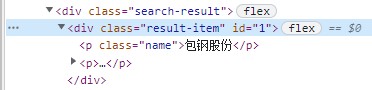
获取元素属性
通过WebElement对象的 get_attribute 方法来获取元素的属性值
比如要获取元素属性class的值【不是tag_name!】,就可以使用
- element.get_attribute(‘class’)
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
wd = webdriver.Chrome(service=Service(r'D:\Software\chromedriver_win32\chromedriver.exe'))
wd.implicitly_wait(10)#最大10秒
wd.get('https://www.byhy.net/_files/stock1.html')
element = wd.find_element(By.ID, '1')
print(element.get_attribute('class'))
获取整个元素对应的HTML
获取整个元素对应的HTML文本内容,可以使用
- element.get_attribute(‘outerHTML‘)
如果,只是想获取某个元素 内部 的HTML文本内容,可以使用
- element.get_attribute(‘innerHTML‘)
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
wd = webdriver.Chrome(service=Service(r'D:\Software\chromedriver_win32\chromedriver.exe'))
wd.implicitly_wait(10)#最大10秒
wd.get('https://www.byhy.net/_files/stock1.html')
element = wd.find_element(By.ID, '1')
print(element.get_attribute('outerHTML'))
print('\n'+'-'*50)
print(element.get_attribute('innerHTML'))

在这里添加您的标题文本
有时候,元素的文本内容没有展示在界面上,如输入框内灰色的字,或者没有完全完全展示在界面上。 这时,用WebElement对象的text属性,获取文本内容,就会有问题。
出现这种情况,可以尝试使用
- element.get_attribute(‘innerText’)
- element.get_attribute(‘textContent’)
使用 innerText 和 textContent 的区别是,前者只显示元素可见文本内容,后者显示所有内容(包括display属性为none的部分)
执行结束退出脚本
wd.quit()
My brother recommended I might like this blog. He used to be entirely right. Leslie Varland