
目录
Xpath选择器
绝对路径选择
从根节点开始的,到某个节点,每层都依次写下来,每层之间用 / 分隔的表达式,就是某元素的 绝对路径。
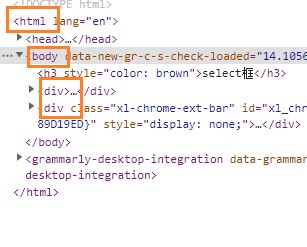
- /html/body/div
就是一个绝对路径的xpath表达式, 等价于 css表达式
- html>body>div
自动化程序要使用Xpath来选择web元素,应该调用 WebDriver对象的方法。
# find_element_by_xpath
# find_elements_by_xpath
elements = driver.find_elements(By.XPATH, "/html/body/div")
相对路径选择
有的时候,我们需要选择网页中某个元素, 不管它在什么位置 。
比如选择示例页面的所有标签名为 div 的元素,如果使用css表达式,直接写一个 div 就行了。
那xpath怎么实现同样的功能呢? xpath需要前面加 // , 表示从当前节点往下寻找所有的后代元素,不管它在什么位置。所以xpath表达式,应该这样写:
- //div
‘//’ 符号也可以继续加在后面,比如,要选择 所有的 div 元素里面的 所有的 p 元素 ,不管div 在什么位置,也不管p元素在div下面的什么位置,则可以这样写
- //div//p
# 如果,要选择 所有的 div 元素里面的 所有子节点 p
elements = driver.find_elements(By.XPATH, "//div//p")
# 如果,要选择 所有的 div 元素里面的 直接子节点 p
elements = driver.find_elements(By.XPATH, "//div/p")
# 如果要选择所有div节点的所有直接子节点,可以使用表达式 //div/*
elements = driver.find_elements(By.XPATH, "//div/*")
elements = driver.find_elements(By.XPATH, "//div/*")
for element in elements:
print(element.get_attribute('outerHTML'))
根据属性选择
Xpath 可以根据属性来选择元素。
根据属性来选择元素 是通过 这种格式来的 [@属性名=’属性值’]
注意:
- 属性名注意前面有个@
- 属性值一定要用引号, 可以是单引号,也可以是双引号
根据 tag名、id、class 选择元素
根据id属性选择
注意“*”
- (By.XPATH, “//*[@id=’west’]”)
如果一个元素class 有多个,比如:
<p id="beijing" class='capital huge-city'>
北京
</p>
如果要选它, 对应的 xpath 就应该是
- (By.XPATH, ‘//p[@class=”capital huge-city”]’)
不能只写一个属性,像这样 //p[@class=”capital”] 则不行
属性值包含字符串
要选择 style属性值 包含 color 字符串的 页面元素 ,可以这样
- //*[contains(@style,’color’)]
CSS:a[href*=”miitbeian”]
要选择 style属性值 以 color 字符串 开头 的 页面元素 ,可以这样:
- //*[starts-with(@style,’color’)]
CSS:a[href^=”http”]
要选择 style属性值 以 某个 字符串 结尾 的 页面元素 ,大家可以推测是
- //*[ends-with(@style,’color’)]
CSS:a[href$=”gov.cn”]
但是,很遗憾,这是xpath 2.0 的语法 ,目前浏览器都不支持
按次序选择
某类型 第几个 子元素
要选择 p类型第2个的子元素,就是
- //p[2]
第几个子元素
也可以选择第2个子元素,不管是什么类型,采用通配符。比如 选择父元素为div的第2个子元素,不管是什么类型
- //div/*[2]
某类型 倒数第几个 子元素
- //p[last()] 选取p类型倒数第1个子元素
- //p[last()-1] 选取p类型倒数第2个子元素
- //div/p[last()-2] 选择父元素为div中p类型倒数第3个子元素
范围选择
次序索引
选取option类型第1到2个子元素
- //option[position()<=2]
- //option[position()<3]
选择class属性为multi_choice的前3个子元素
- //*[@class=’multi_choice’]/*[position()<=3]
选择class属性为multi_choice的后3个子元素
- //*[@class=’multi_choice’]/*[position()>=last()-2]
组选择、父节点、兄弟节点
组选择
css有组选择,可以同时使用多个表达式,多个表达式选择的结果都是要选择的元素,css 组选择,表达式之间用 逗号 隔开。
xpath也有组选择, 是用 竖线 隔开多个表达式。比如,要选所有的option元素 和所有的 h4 元素,可以使用
- //option | //h4
option , h4 等同于CSS选择器
再比如,要选所有的 class 为 single_choice 和 class 为 multi_choice 的元素,可以使用
- //[@class=’single_choice’] | //[@class=’multi_choice’]
.single_choice , .multi_choice 等同于CSS选择器
选择父节点
xpath可以选择父节点, 这是css做不到的。某个元素的父节点用 /.. 表示,比如,要选择 id 为 china 的节点的父节点,可以这样写
- //*[@id=’china’]/..
当某个元素没有特征可以直接选择,但是它有子节点有特征, 就可以采用这种方法,先选择子节点,再指定父节点。
还可以继续找上层父节点,比如
- //*[@id=’china’]/../../..
兄弟节点选择
前面学过 css选择器,要选择某个节点的后续兄弟节点,用 波浪线。
xpath也可以选择 后续 兄弟节点,用这样的语法
- following-sibling::
比如,要选择 class 为 single_choice 的元素的所有后续兄弟节点
- //[@class=’single_choice’]/following-sibling::
.single_choice ~ * 等同于CSS选择器
如果,要选择后续节点中的div节点, 就应该这样写
- //*[@class=’single_choice’]/following-sibling::div
xpath还可以选择 前面的 兄弟节点,用这样的语法
- preceding-sibling::
比如,要选择 class 为 single_choice 的元素的所有前面的兄弟节点
- //[@class=’single_choice’]/preceding-sibling::
而CSS选择器目前还没有方法选择前面的 兄弟节点。
CSS 和 XPath 混用
我们来看一个例子,先选择示例网页中,id是china的元素。然后通过这个元素的WebElement对象,使用find_elements_by_xpath,选择里面的p元素
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
wd = webdriver.Chrome(service=Service(r'D:\Software\chromedriver_win32\chromedriver.exe'))
wd.implicitly_wait(5)
wd.get('https://cdn2.byhy.net/files/selenium/test1.html')
# 先寻找id是china的元素
china = wd.find_element(By.ID, 'china')
# 再选择该元素内部的p元素
elements = china.find_elements(By.XPATH, '//p')
# 打印结果
for element in elements:
print('----------------')
print(element.get_attribute('outerHTML'))
运行发现,打印的 不仅仅是 china内部的p元素, 而是所有的p元素。
要在某个元素内部使用xpath选择元素, 需要 在xpath表达式最前面加个点
# 只出现在Css & XPath混用情况
elements = china.find_elements(By.XPATH, './/p')
I want to say thanks so much to acknowledge your caring about the value of your content, and thus your readers. Deangelo Merkey
I appreciate you sharing this article post. Really looking forward to read more. Great. Shalna Ringo Quenby
I am in fact delighted to read this website posts which includes lots of valuable information, thanks for providing such data. Jordon Simens