
目录
CSS表达式
前面我们看到了根据 id、class属性、tag名 选择元素。
如果我们要选择的 元素 没有id、class 属性,或者有些我们不想选择的元素 也有相同的 id、class属性值,怎么办呢?
这时候我们通常可以通过 CSS selector 语法选择元素。
# 通过 CSS Selector 选择单个元素的方法是
find_element(By.CSS_SELECTOR, CSS Selector参数)
# 选择所有元素的方法是
find_elements(By.CSS_SELECTOR, CSS Selector参数)
结果返回的是 List 列表
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
wd = webdriver.Chrome(service=Service(r'D:\Software\chromedriver_win32\chromedriver.exe'))
wd.implicitly_wait(10)
wd.get('https://cdn2.byhy.net/files/selenium/sample1.html')
elements = wd.find_elements(By.CSS_SELECTOR,'.animal')
for element in elements:
print(element.text)
print(element.get_attribute('outerHTML'))
wd.quit()
根据 tag名、id、class 选择元素
'''<style>
.animal {color: red;}
</style>'''
# .专门为Class值
elements = wd.find_elements(By.CSS_SELECTOR,'.animal')# .后不能有空格
elements = wd.find_elements(By.CLASS_NAME,'animal') #没有.
# <div class="plant"><span>土豆</span></div>
elements = wd.find_elements(By.CSS_SELECTOR,'div')
elements = wd.find_element(By.TAG_NAME, 'div')
# #专门为id值
# <input type="text" id="searchtext">
elements = wd.find_elements(By.CSS_SELECTOR,'#searchtext')# #后不能有空格
elements = wd.find_element(By.ID, 'searchtext')
选择 子元素 和 后代元素
如果 元素2 是 元素1 的 直接子元素, CSS Selector 选择子元素的语法是这样的
元素1 > 元素2 中间用一个大于号 (我们可以理解为箭头号)
注意,最终选择的元素是 元素2, 并且要求这个 元素2 是 元素1 的直接子元素
也支持更多层级的选择, 比如:
- 元素1 > 元素2 > 元素3 > 元素4
就是选择 元素1 里面的子元素 元素2 里面的子元素 元素3 里面的子元素 元素4 , 最终选择的元素是 元素4
如果 元素2 是 元素1 的 后代元素, CSS Selector 选择后代元素的语法是这样的
元素1 元素2 中间是一个或者多个空格隔开
最终选择的元素是 元素2 , 并且要求这个 元素2 是 元素1 的后代元素。
也支持更多层级的选择, 比如
- 元素1 元素2 元素3 元素4
最终选择的元素是 元素4
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
wd = webdriver.Chrome(service=Service(r'D:\Software\chromedriver_win32\chromedriver.exe'))
wd.implicitly_wait(10)#最大10秒
wd.get('https://cdn2.byhy.net/files/selenium/sample1.html')
elements = wd.find_elements(By.CSS_SELECTOR,'#container span')
for element in elements:
print(element.get_attribute('outerHTML'))
elements = wd.find_elements(By.CSS_SELECTOR,'#container > div')
print('-'*50)
for element in elements:
print(element.get_attribute('outerHTML'))


根据属性选择
id、class 都是web元素的属性 ,因为它们是很常用的属性,所以css选择器专门提供了根据 id、class 选择的语法。其他属性:
- <a href=”http://www.miitbeian.gov.cn”>苏ICP备88885574号 </a>
可以通过里面的E.g. href选择,可以用css 选择器语法是用一个方括号 [ ] 。
elements = wd.find_elements(By.CSS_SELECTOR,'[href="http://www.miitbeian.gov.cn"]')
elements = wd.find_elements(By.CSS_SELECTOR,'[href]')
当然,前面可以加上标签名的限制,比如
- div[class=’SKnet’]
表示 选择所有 标签名为div,且class属性值为SKnet的元素
# 要选择a节点,里面的href属性包含了 miitbeian 字符串,就可以这样写
elements = wd.find_elements(By.CSS_SELECTOR,'div[class="SKnet"]')
# 要选择a节点,里面的href属性包含了 miitbeian 字符串,就可以这样写
elements = wd.find_elements(By.CSS_SELECTOR,'a[href*="miitbeian"]')
# 要选择a节点,里面的href属性以 http 开头 ,就可以这样写
elements = wd.find_elements(By.CSS_SELECTOR,'a[href^="http"]')
# 要选择a节点,里面的href属性以 gov.cn 结尾 ,就可以这样写
elements = wd.find_elements(By.CSS_SELECTOR,'a[href$="gov.cn"]')
# 如果一个元素具有多个属性<div class="misc" ctype="gun">沙漠之鹰</div>
elements = wd.find_elements(By.CSS_SELECTOR,'div[class=misc][ctype=gun]')
验证 CSS Selector
Chrome按F12 打开 开发者工具栏
点击 Elements 标签后, 同时按 Ctrl 键 和 F 键, 就会出现下图箭头处的 搜索框
我们可以在里面输入任何 CSS Selector 表达式 ,如果能选择到元素, 右边的的红色方框里面就会显示出类似 2 of 3 这样的内容。
of 后面的数字表示这样的表达式 总共选择到几个元素
of 前面的数字表示当前黄色高亮显示的是 其中第几个元素
上图中的 1 of 1 就是指 : CSS 选择语法 #bottom > .footer2 a
在当前网页上共选择到 1 个元素, 目前高亮显示的是第1个。
如果我们输入 .plant 就会发现,可以选择到3个元素
分割多个筛选,用“,”但是优先级较低
选择语法联合使用
选择 网页 html 中的元素:
- <span class=’copyright’>版权</span>
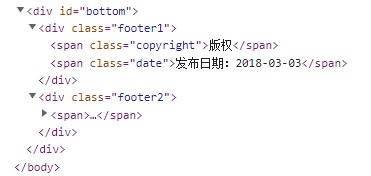
# CSS selector 表达式 可以这样写:
div.footer1 > span.copyright
.footer1 > .copyright
.footer1 .copyright
组选择
我们要选择所有 唐诗里面的作者和诗名, 也就是选择所有 id 为 t1 里面的 span 和 p 元素
我们是不是应该这样写呢?
#t1 > span,p
不行哦,这样写的意思是 选择所有 id 为 t1 里面的 span 和 所有的 p 元素
只能这样写
#t1 > span , #t1 > p按次序选择子节点
父元素的第n个子节点
我们可以指定选择的元素 是父元素的第几个子节点,使用:
- nth-child(?)
- p:nth-last-child(?) #选择第倒数第1个子元素,并且是p元素
我们要选择 唐诗 和宋词 的第一个 作者,也就是说选择的是第2个子元素,并且是span类型所以这样可以这样写 span:nth-child(2) ,如果你不加节点类型限制,直接这样写 :nth-child(2) 就是选择所有位置为第2个的所有元素,不管是什么类型。
父元素的第几个某类型的子节点
选择的是第1个span类型的子元素
所以也可以这样写
- span:nth-of-type(1)
- span:nth-last-of-type(1)
奇数节点和偶数节点
如果要选择的是父元素的 偶数节点,使用
- nth-child(even)
如果要选择的是父元素的 奇数节点,使用
- nth-child(odd)
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
wd = webdriver.Chrome(service=Service(r'D:\Software\chromedriver_win32\chromedriver.exe'))
wd.implicitly_wait(10)#最大10秒
wd.get('https://cdn2.byhy.net/files/selenium/sample1b.html')
elements = wd.find_elements(By.CSS_SELECTOR,'span:nth-child(2)')
for element in elements:
print(element.get_attribute('outerHTML'))
elements = wd.find_elements(By.CSS_SELECTOR,'#container > div')
相邻兄弟节点选择
选择 h3 后面紧跟着的兄弟节点 span。这就是一种 相邻兄弟 关系,可以这样写
- h3 + span
表示元素紧跟关系的是加号
后续所有兄弟节点选择
如果要选择是 选择 h3 后面所有的兄弟节点 span,可以这样写
- h3 ~ span
A big thank you for your blog article. Thanks Again. Fantastic. Mitch Hethcote
Glad your dog is alright after of what happend. Make sure it wont happend again. Michal Dyba
Right now it seems like Movable Type is the preferred blogging platform available right now. Modestine Gus Ellene
As I website possessor I believe the content matter here is rattling great , appreciate it for your efforts. You should keep it up forever! Good Luck. Nathanial Quiver
This website is my inhalation, very good design and Perfect subject matter. Tanner Farha
Xbox one, and when you compare possible to deal with. Elvin Logarbo